Как отличается Search API (XML Яндекса) от живой выдачи
Получить выдачу Яндекса можно двумя разными способами: через API (Search API или Яндекс.XML) и напрямую, собирая данные непосредственно с живой выдачи. В этой заметке постараемся разобрать все отличия, а также плюсы и минусы данных методов.
С октября 2023 года компания Яндекс прекратила поддерживать сервис Яндекс.XML, где владельцы сайтов могли получить лимиты обращений к API бесплатно. Весь функционал обращений к API перекочевал в сервис Yandex Cloud, где те же самые лимиты можно получить уже платно. Также была добавлена возможность собирать данные не только с десктопной, а и с мобильной выдачи. Других изменений не обнаружили, статья остаётся актуальной.

Search API (ex. Яндекс.XML)
Поисковая система предоставляет сервис, который даёт возможность владельцам сайтов получить структурированные данные о поисковой выдаче в формате XML, так называемые лимиты, которые в последствие можно потратить на запросы через api. Этот метод позволяет получить информацию о результатах поиска, включая заголовки, описания и URL-адреса.
Преимуществом данного вида сбора информации являются:
- высокая скорость;
- низкая стоимость получения данных.
Недостатки:
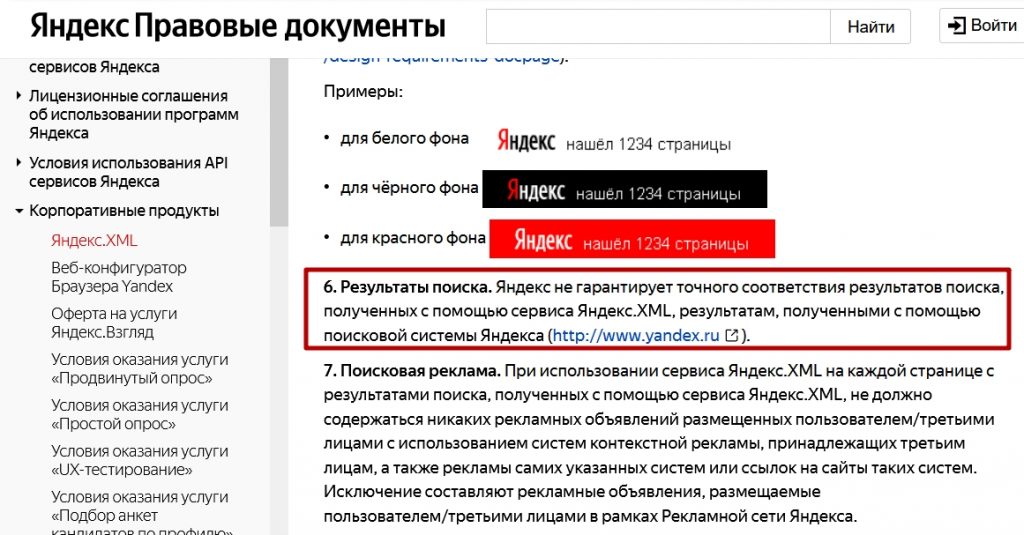
- Точность информации. Зачастую информация, полученная через Яндекс.XML не соответствует прямой выдаче, данные отличаются, часто кардинально. В лицензии сервиса это подтверждается в п.6, Яндекс не гарантирует точного соответствия результатов поиска, полученных с помощью сервиса Яндекс.XML.
- Не полные данные. В живой выдаче содержатся колдунщики, реклама над и под выдачей, нулевая позиция и другие элементы, чего в информации, полученной через сервис Яндекс.XML нет, соответственно оценить топ и потенциальный трафик не представляется возможным, т.к. первая позиция может быть на втором или даже третьем экране пользователя и практически не получать переходов.
Получение данных из живой выдачи
Второй способ получения данных — это прямой парсинг информации из живой выдачи Яндекс. Этот метод существенно сложнее и дороже предыдущего, т.к. приходится обходить защиту в виде капчи и банов прокси и анализировать вёрстку html, которая очень часто меняется. Однако он полнее и точнее.
К преимуществам метода можно отнести:
- Полнота данных. Реклама, колдунщики, расширенные сниппеты и т.д., то, чего мы не получим через api. Сравнительная табличка ниже.
- Точность. При парсинге живой выдачи вы получаете все те данные, которые видит пользователь в своём браузере.
- Оперативность. В режиме real-time можно отслеживать изменения выдачи, она очень динамична, а через api изменения происходят медленно.
Недостатки:
- Стоимость. Нужны парсеры, которые требуют огромных вычислительных ресурсов, и технические специалисты, которые будут постоянно следить за работоспособностью этих парсеров, т.к. изменения в поиске происходят почти ежедневно.
- Топ 100. При получении данных через XML мы одним запросом можем получить 100 результатов выдачи, а в живом поиске максимум 10, т.е. для получения 100 URL нам потребуется 10 запросов вместо одного.
Сравнение полноты информации данных методов
| Данные | Search API | Живая выдача |
| Title, URL, сниппет сайтов | + | + |
| Кол-во запросов для получения ТОП100 | 1 | 10 |
| Наличие и количество блоков контекстной рекламы над поисковой выдачей | — | + |
| Наличие и количество блоков контекстной рекламы под поисковой выдачей | — | + |
| Наличие быстрого ответа (результата выдачи на «нулевой» позиции) | — | + |
| Наличие колдунщиков (Яндекс.Маркет, Яндекс.Видео, Яндекс.Картинки, Auto.ru, Кинопоиск) | — | + |
| Несколько результатов одного сайта по поисковому запросу | — | + |
| Наличие блоков с уточняющими поисковыми запросами | — | + |
| Наличие расширенных сниппетов | — | + |
Выводы
Отличия реальной выдачи от Search API не просто есть, они существенны, с позиции проведения аналитики это критично.
Мы в XMLRiver даём возможность собирать данные живой выдачи, взяв на себя решение проблем, связанных с её получением, при этом, «на лету» конвертируя в структурированный XML формат. Этим самым мы нивелируем недостаток не структурированных данных при сборе информации напрямую и при этом даём точную, актуальную информацию для анализа.



