Программа для работы с сервисом - XMLRiver.Parser
Скачать XMLRiver.Parser Зеркало Посмотреть обучающее видео
После скачивания, программа предложит согласиться с условиями использования.
Обратите внимание! Программа XMLRiver.Parser поставляется как есть, к тому же, это всего лишь утилита, дающая клиентам способ получать информацию от сервиса без навыков и необходимости программирования для получения данных по API. Программа умеет сохранять далеко не всю информацию, которую можно получить по API.
Внимание! Программа до выгрузки в csv хранит полученные данные в оперативной памяти устройства. Если произойдёт сбой, уже собранные данные могут пропасть, этому не рекомендуем загружать в программу много фраз. Разбивайте и собирайте частями, чтобы снизить риск потери данных.

Дальше нужно в интерфейсе самой программы пройти авторизацию. При этом не будет необходимости вводить URL для запросов на каждой вкладке, они определятся автоматически.
Поисковая выдача Google
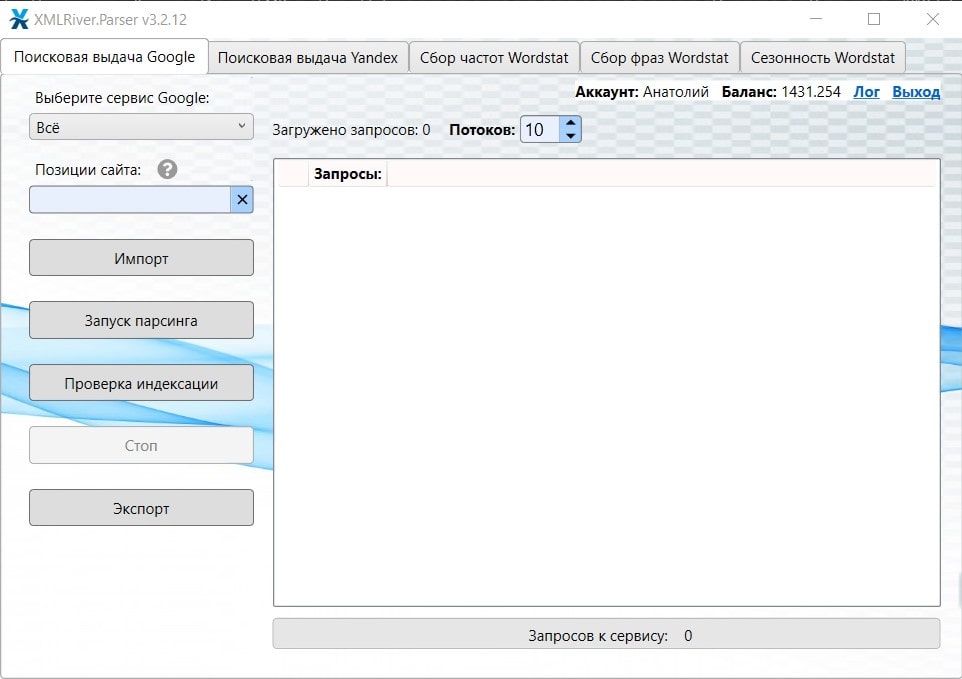
В первой вкладке «Поисковая выдача Google» слева в выпадающем списке есть возможность выбрать, что мы будем парсить:
- Всё – это поисковая выдача
- Картинки
- Новости
- Покупки
- Вопросы по теме
- Google Maps
Перед парсингом необходимо импортировать ключевые фразы, по которым мы будем собирать данные, если нам нужны выдача, картинки, новости, покупки или вопросы по теме. Если же нужна проверка индексации, импортируем список ULR Вашего сайта для проверки. Импортируемые файлы - *.txt , где фраза или URL каждый с новой строки.
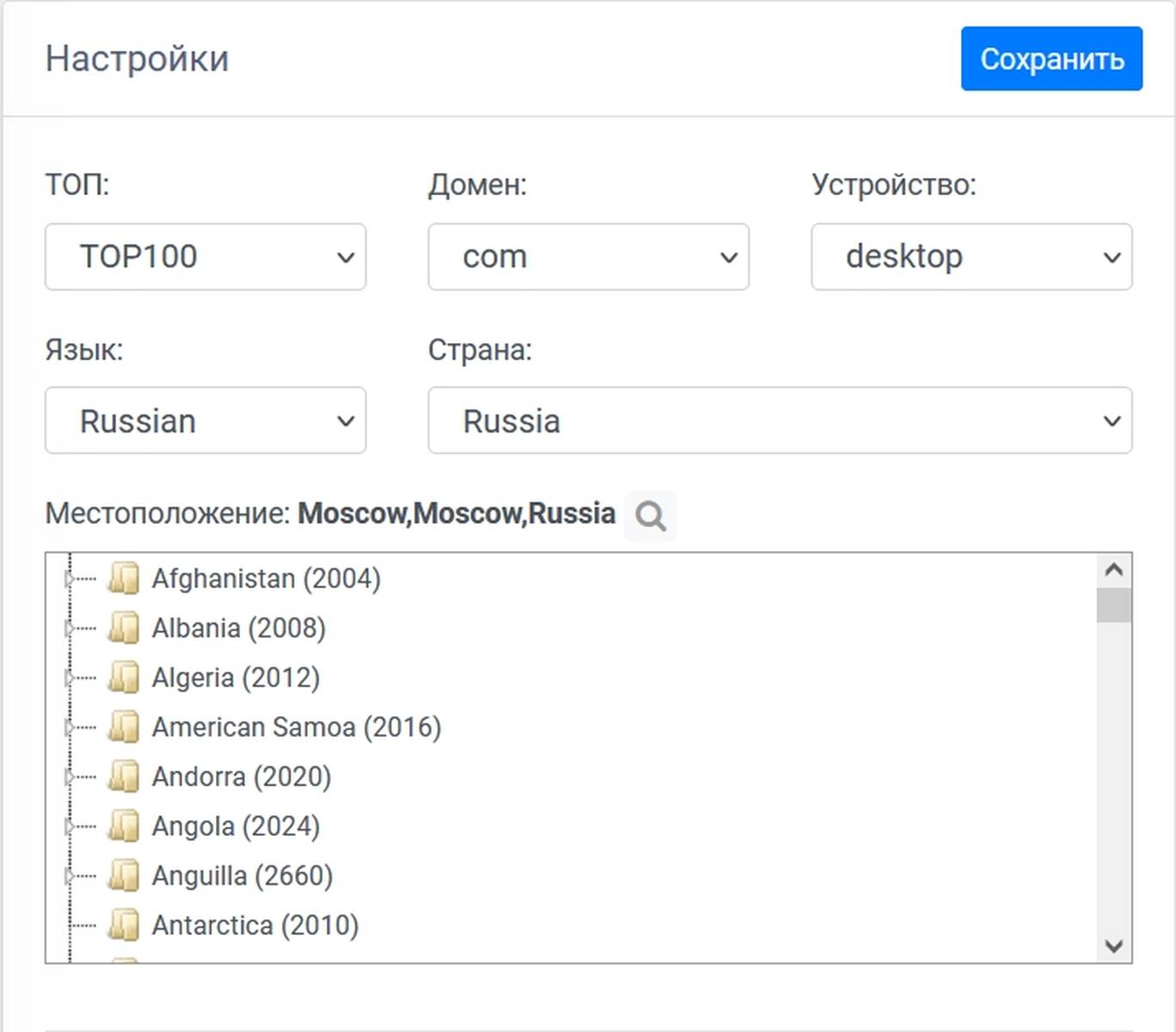
После импорта в личном кабинете сервиса нужно выставить ГЕО настройки, по которым будет осуществляться сбор и нажать кнопку «Сохранить».
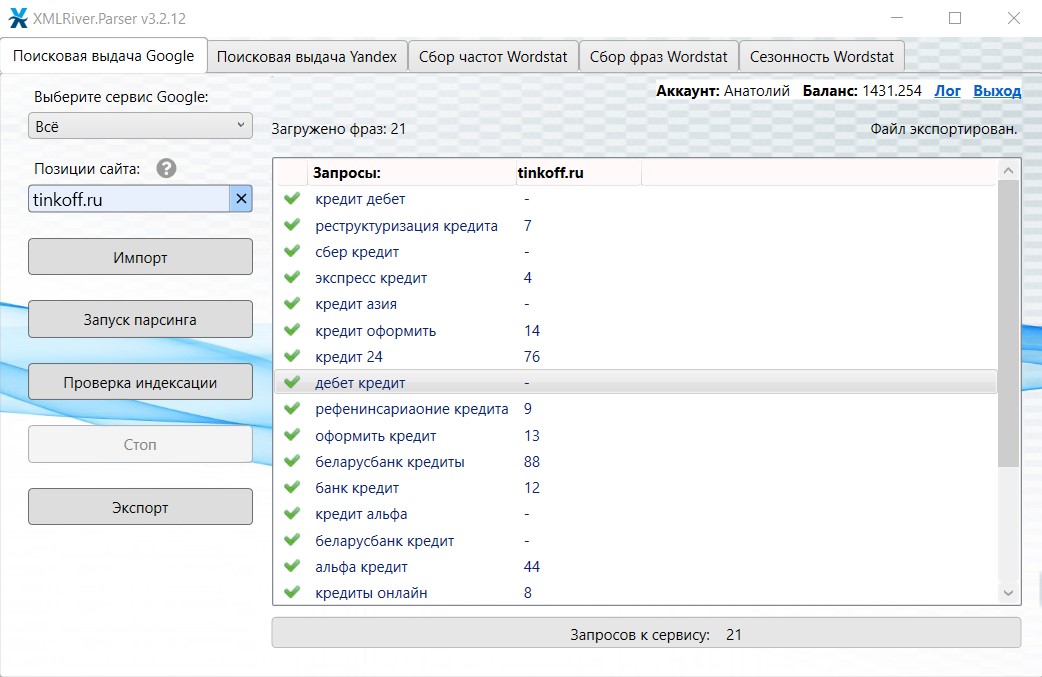
Дальше нажимаем «Запуск парсинга» или «Проверка индексации» в зависимости от целей. Программа зелёными галочками покажет, по каким фразам собрана выдача или по каким URL проверена индексация и прогресс-бар. Процесс парсинга можно остановить и возобновить без потери данных, если не закрывать программу.
В выпадающих списках "Всё" и "Новости" можно указать сайт для быстрой проверки позиций. Просто указываем имя домена и смотрим, какие позиции он занимает в выдаче по ключевым словам, где собрана сама выдача. Можно по очереди указывать разные сайты, программа перестроит столбец с позициями.
После сбора можно экспортировать данные в csv формат. Предварительно программа покажет опции экспорта:
В экспортируемом файле будут такие столбцы:
Query – искомая фраза, Founded_results – найдено результатов, SERP_Title – тайтл документа, SERP_Url – URL документа, SERP_Snippet – сниппет документа, Top_ADS_Title – Тайтл рекламного объявления над выдачей, Top_ADS_Url – URL рекламного объявления над выдачей, Top_ADS_Snippet – сниппет рекламного объявления над выдачей, Bottom_ADS_Title Тайтл - рекламного объявления под выдачей, Bottom_ADS_Url - URL рекламного объявления под выдачей, Bottom_ADS_Snippet - сниппет рекламного объявления под выдачей, ZeroPosition_Title – Тайтл нулевой позиции, ZeroPosition_Url – URL нулевой позиции, ZeroPosition_Snippet – сниппет нулевой позиции,( Local_Results_Title, Local_Results_Url, Local_Results_Rating, Local_Results_PlaceId) – данные по карте в выдаче, Related_Searches – связанные поисковые запросы, (Related_Questions_Question, Related_Questions_Url, Related_Questions_Title, Related_Questions_Snippet) – вопросы по теме, которые отображаются в выдаче без раскрытия, HighlightedWords – подсвеченные слова и фразы в выдаче, Позиции сайта в поисковой системе - если такой был введён в соответствующем поле в интерфейсе программы.
Обратите внимание, эти данные будут в файле экспорта, если предварительно в личном кабинете, в настройках сбора проставить соответствующие чекбоксы:
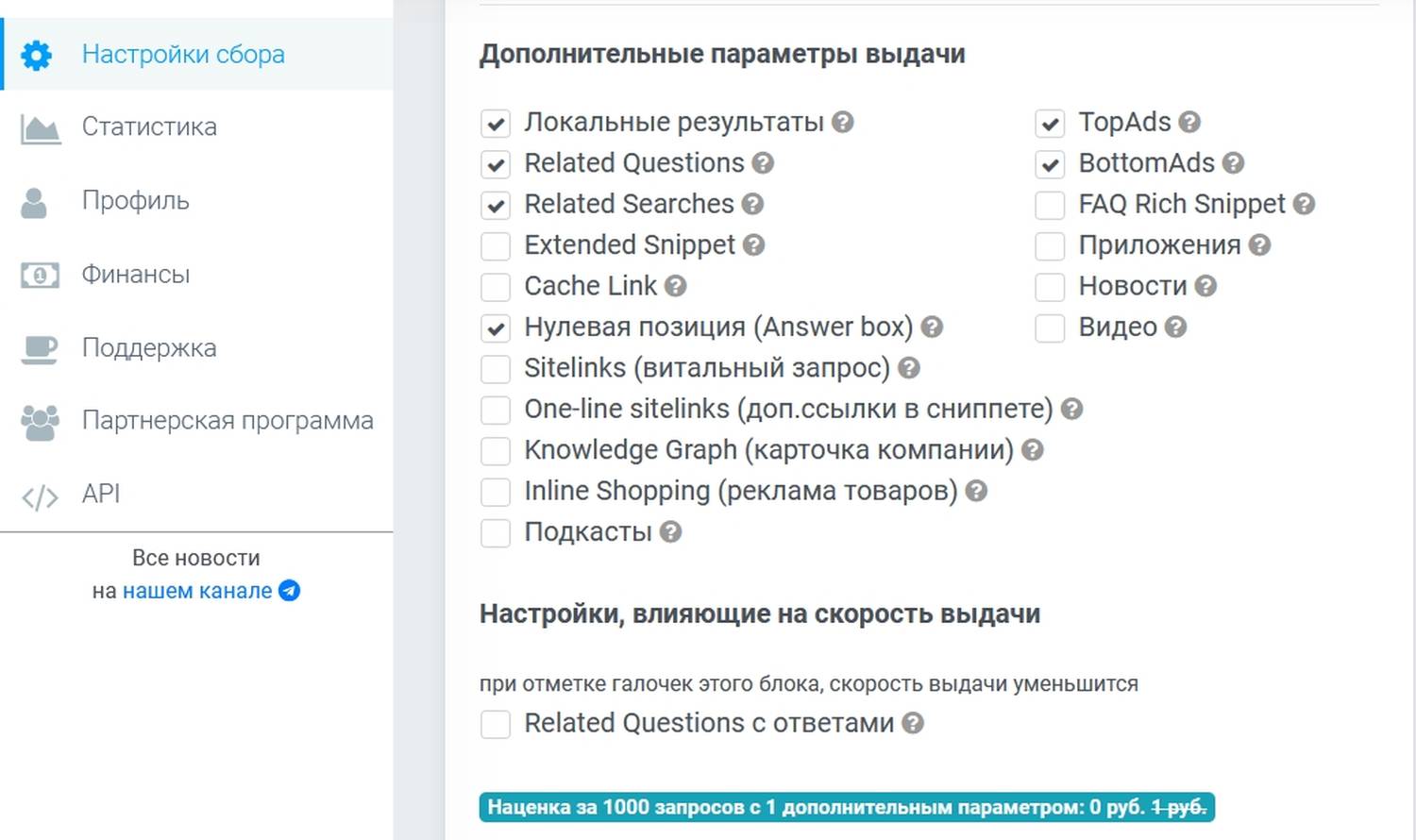
При сборе поисковой выдачи мы сохраняем Related Questions (Вопросы по теме) только те, которые присутствуют при открытии страницы. Однако если открыть один из вопросов, подгружаются ещё. Для того, чтобы собрать до 50 таких вопросов, используйте вариант «Вопросы по теме» в выпадающем списке программы.
Поисковая выдача Яндекс
В следующей вкладке мы можем собирать такие сервисы Яндекса:
- Поиск
- Предложения
При выборе «Поиск» мы будем собирать данные с поисковой выдачи, здесь всё очень похоже на сбор данных с Google, те же настройки, та же последовательность действий.
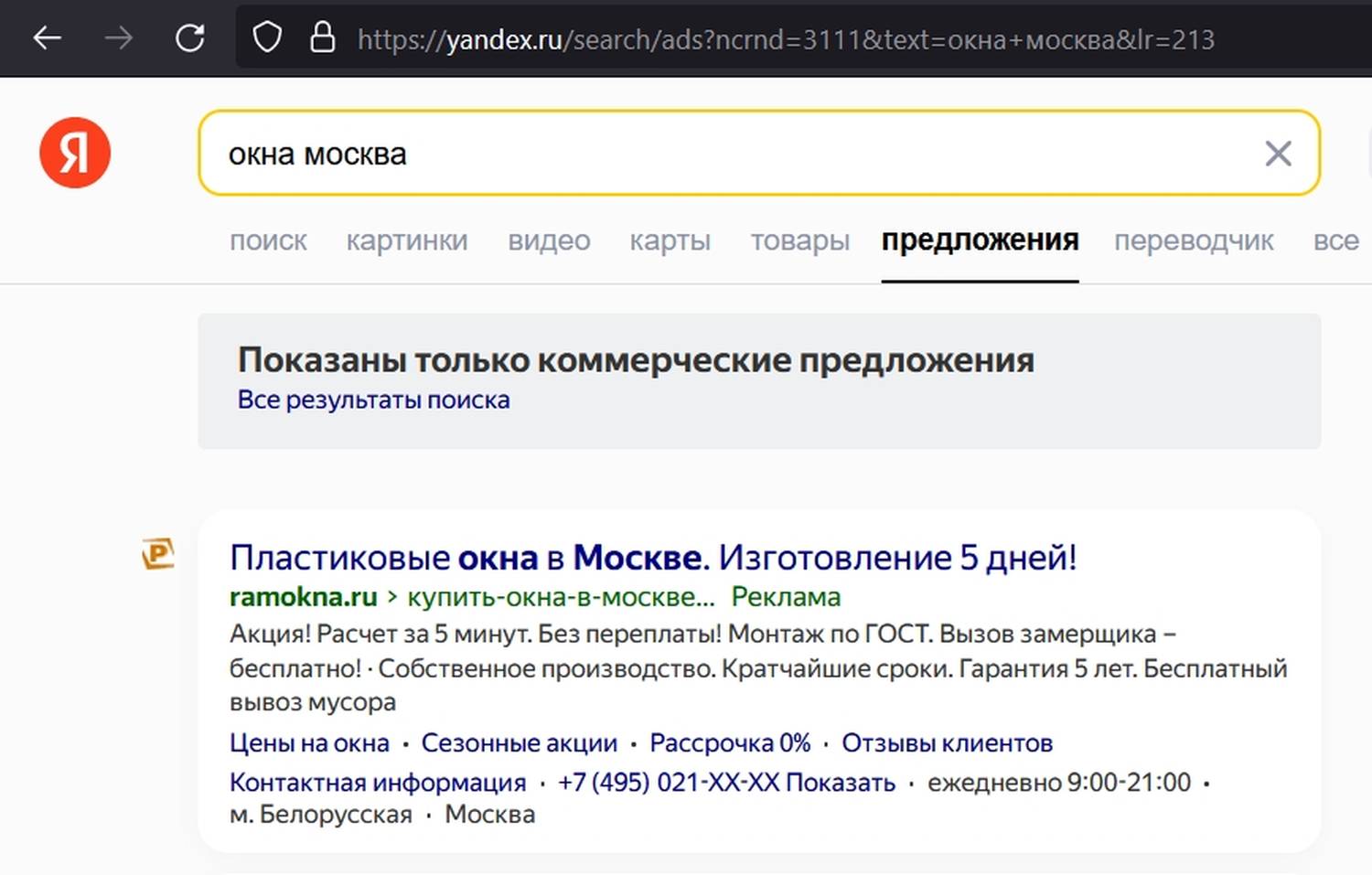
Предложения – это вкладка в Яндексе, где показываются только коммерческие предложения, пример.
Wordstat
Следующие три вкладки программы отвечают за сбор сервиса Яндекса Wordstat:
- Сбор частот
- Сбор фраз
- Сезонность
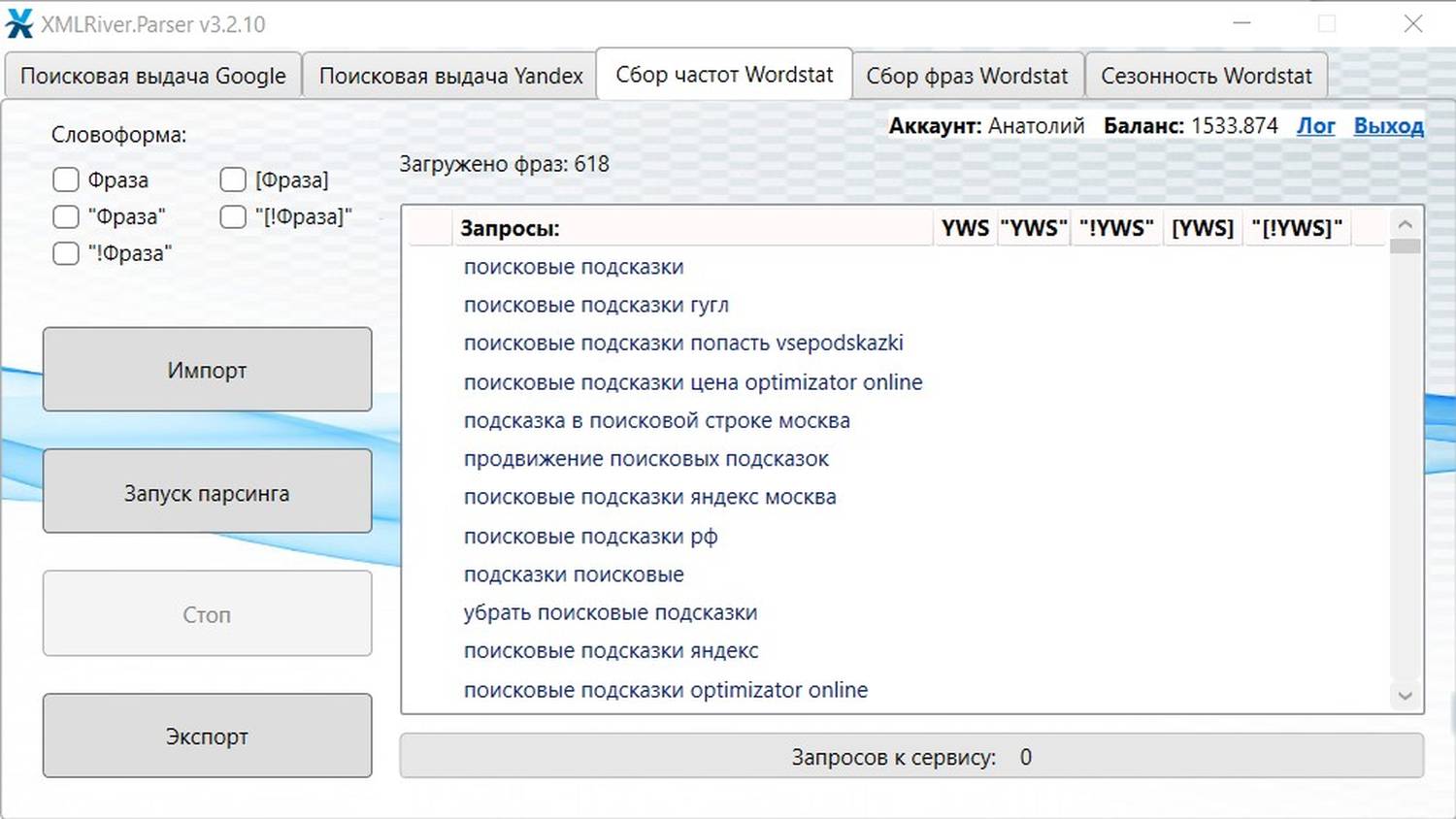
В сборе частот поддерживается 5 словоформ, достаточно отметить интересующие и нажать на «Запуск парсинга».
В сборе фраз программа позволяет настроить какое количество страниц парсить, диапазон частот, глубину парсинга, возможность не раскрывать (не парсить) фразы, которые уже полностью собраны и учёт минус-слов.
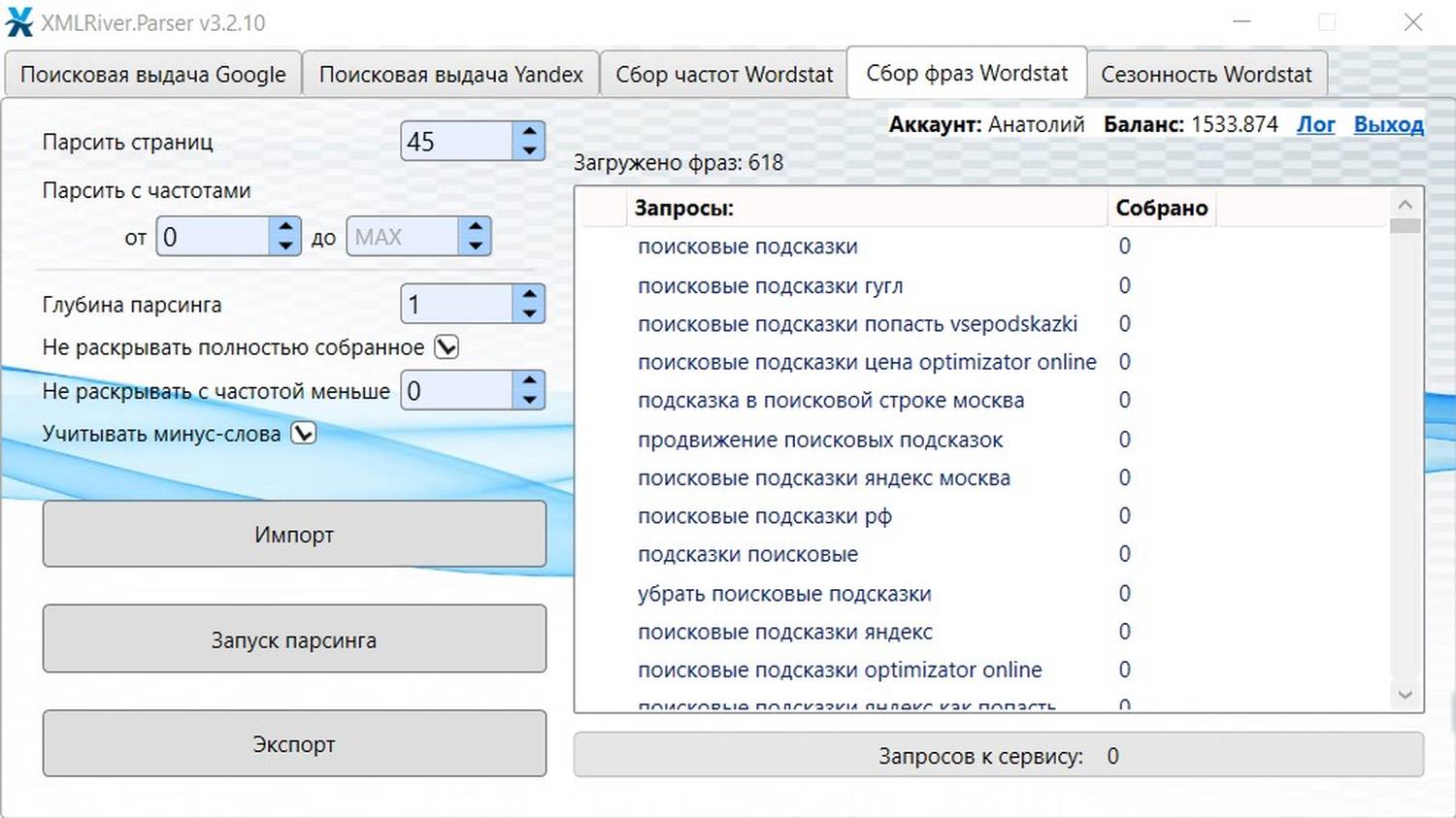
Учитывать минус-слова – например, вы импортировали в программу фразу:
поисковые подсказки – яндекс
и поставили глубину парсинга 1. В таком случае программа соберёт сначала все ключевые фразы по исходной маске (поисковые подсказки –яндекс), а потом начнёт использовать как маски вновь собранные ключевые слова. При этом минус-слово «яндекс» будет подставлено в каждую из новых масок при включенном чекбоксе.
Не рекомендуем устанавливать значение выше 0, если точно не уверены, зачем это вам надо!
В сборе сезонности программа даёт возможность собирать данные по месяцам и неделям. После импорта ключевых слов и запуска парсинга программа отобразит в интерфейсе минимум, максимум и среднее значение.
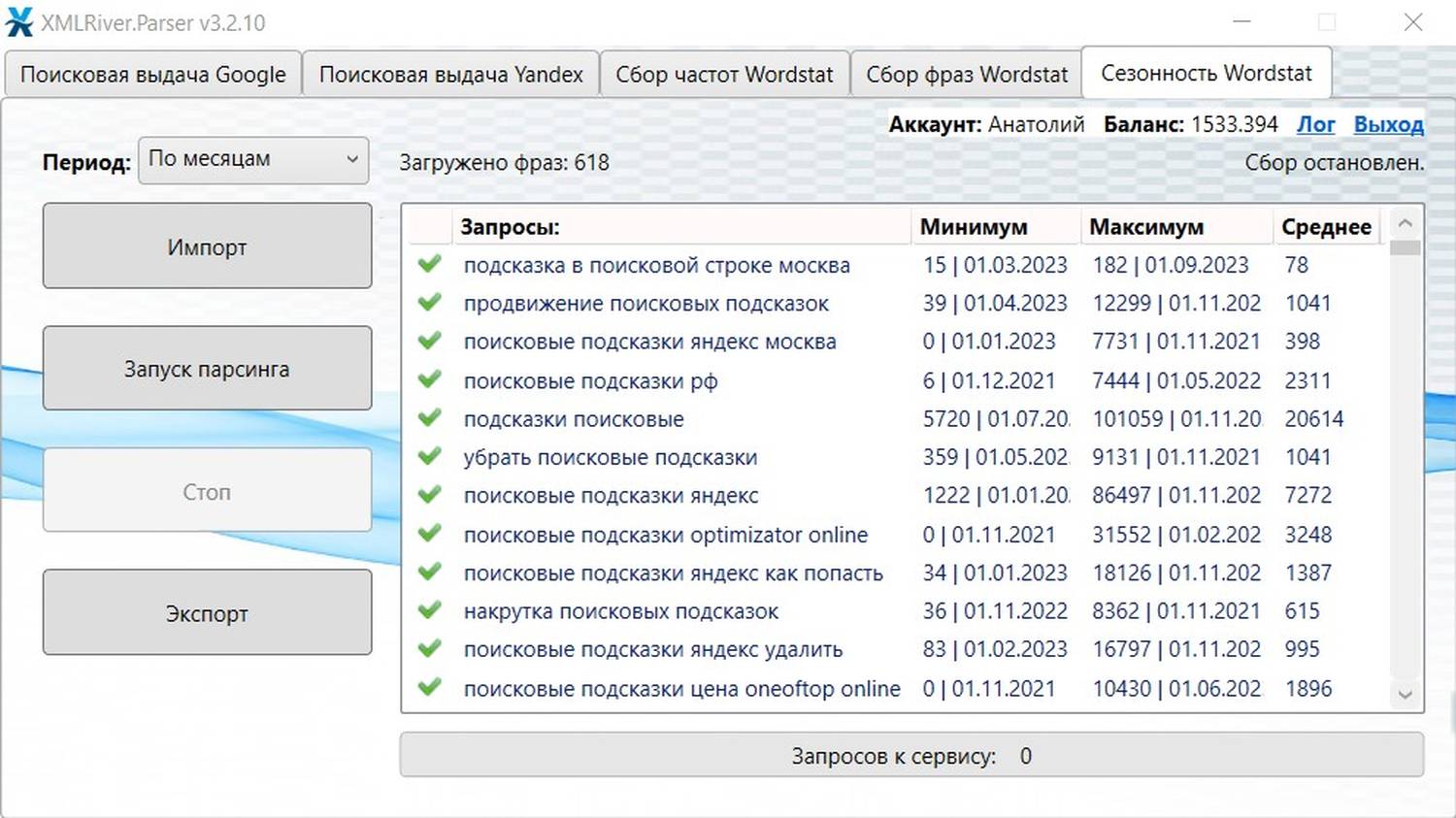
А после экспорта результатов сбора в csv файле будет вот такая структура
