Как парсить Google в XMLRiver
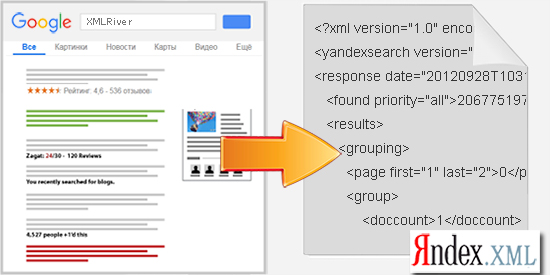
Друзья, с этой статьи мы начинаем ведение блога и в первую очередь расскажем, как можно взаимодействовать с сервисом XMLRiver и какие преимущества парсинга выдачи Гугла таким способом в отличие от других средств сбора.
Сервис работает с двумя поисковыми системами: Google и Яндекс. Здесь мы подробно рассмотрим работу с ПС Google, однако работа с Яндексом почти ничем не отличается, кроме выдаваемых дополнительных параметров.
Как работать с сервисом
XMLRiver выдаёт данные в распространённом и очень удобном API формате XML.Yandex. Данный формат удобен тем, что почти любой инструмент сеошника умеет с ним работать.
Однако у поисковой системы Google есть и отличающиеся от Яндекса блоки выдачи, поэтому в XMLRiver есть некоторые дополнения, которых нет в формате XML.Yandex, они описаны в нашем API и о них речь пойдёт ниже.
Для начала работы с сервисом достаточно зарегистрироваться и пополнить счёт. В разделе «Покупка запросов» есть строка «URL для запросов» с уникальными идентификаторами вашего аккаунта, которые в любой момент можно поменять кнопкой «Сменить ключ». С помощью этого URL мы и будем делать запросы к поисковой системе Google.

Сервис по умолчанию для любого аккаунта позволяет собирать данные в 10 потоков. При этом количестве потоков, в среднем, получается собрать около 16 тысяч запросов в час. Если Вам надо больше, через техподдержку можно увеличить количество потоков и, соответственно, скорость сбора данных.
Настройки параметров необходимой выдачи можно корректировать как внутри аккаунта, так и посредством передачи вместе с GET запросом.
Дополнительные параметры выдачи Google
В данный момент сервис показывает такие дополнительные блоки выдачи:
- Нулевая позиция
- Sitelinks (витальный запрос)
- One-line sitelinks (доп.ссылки в сниппете)
- Related Questions
- Related Searches
- Extended Snippet
- Knowledge Graph (карточка компании)
- Локальные результаты
- Cache Link
- TopAds (рекламный блок над выдачей)
- BottomAds (рекламный блок внизу страницы)
- FAQ Rich Snippet
Подробно Вы можете посмотреть в личном кабинете, а тут вкратце о некоторых:
Нулевая позиция
Быстрый ответ (Answer box) Google со ссылкой — это специальный элемент Google, обведённый серой рамкой, появляется над органическими результатами Google и напрямую отвечает на ваш вопрос.
Типы быстрых ответов:
- Текст;
- Список;
- Таблица.
При выборе этой опции в результатах ответа Вы получите ссылку и title.
Обратите внимание! Быстрые ответы бывают со ссылкой и без ссылки. При выборе этой опции предоставляются только быстрые ответы со ссылкой.
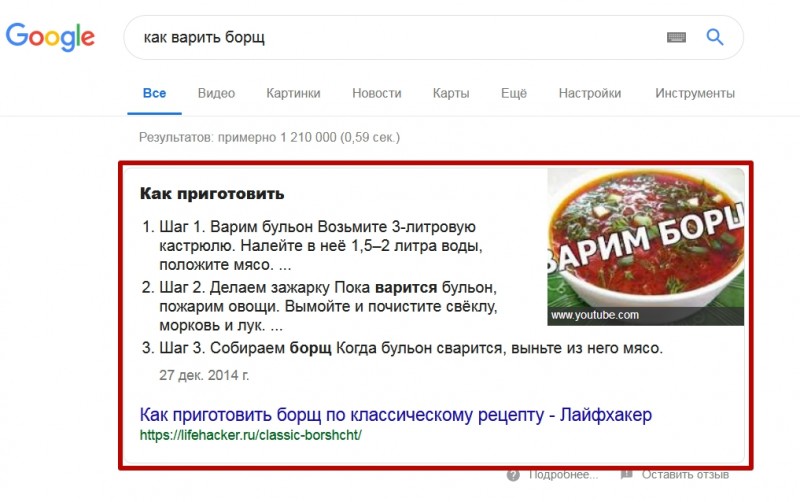
Sitelinks (витальный запрос)
Когда запрос содержит название бренда и на первой позиции показывается сайт с дополнительными ссылками, иногда с окном поиска по сайту. При выборе этой опции вы получите дополнительные ссылки первого сайта.
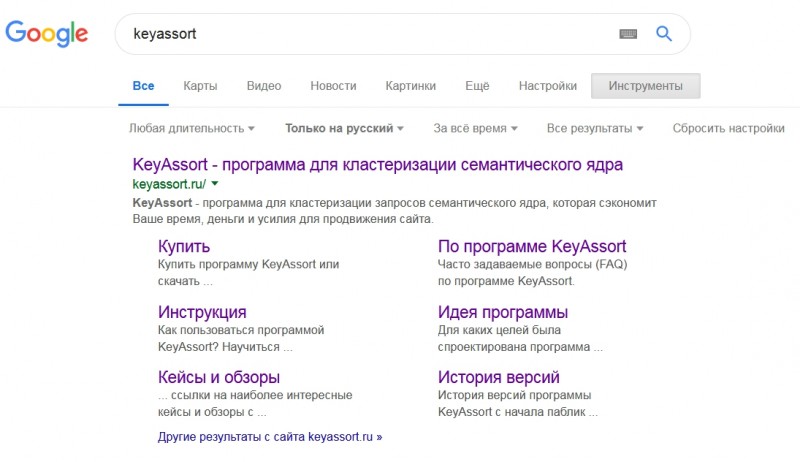
One-line sitelinks (доп. ссылки в сниппете)
Для некоторых документов в результатах поиска показываются дополнительные ссылки в одну строчку.
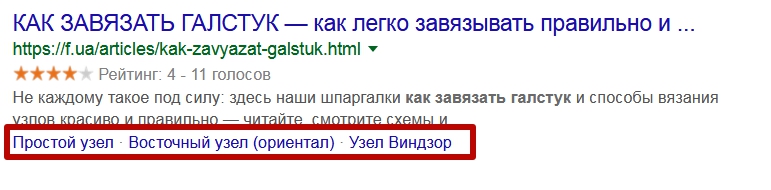
Related Questions
Похожие запросы, которые пользователи часто задают вместе с данным.

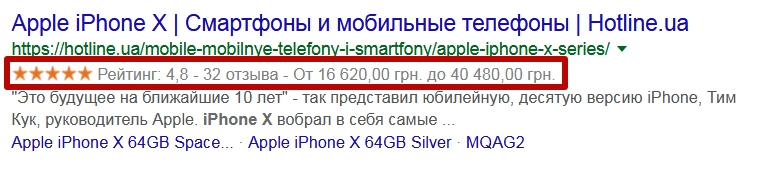
Extended Snippet
Расширенный сниппет. Для некоторых сайтов в сниппете могут дополнительно отображаться: рейтинг, цена, отзывы, наличие товара.
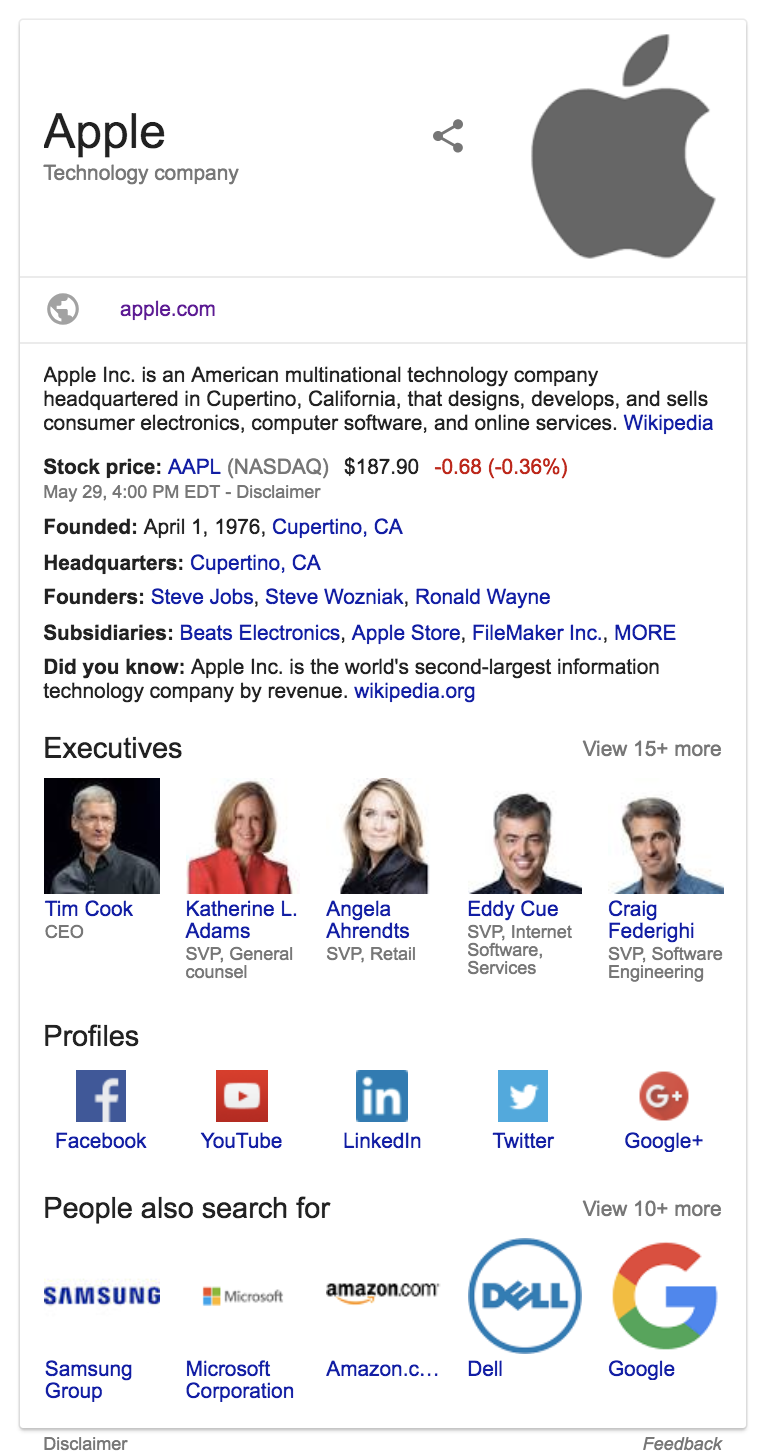
Knowledge Graph
Графа знаний или Knowledge Graph показывает справа от поиска краткую информацию о:
- Компаниях
- Людях
- Различных вещах
Сервис XMLRiver показывает только карточки компаний.
Инструменты для взаимодействия
С сервисом XMLRiver можно работать любым инструментом, который способен взаимодействовать с форматом XML.Yandex. Однако некоторые программы, в которых нет интеграции с сервисом, могут показывать, что данные собраны с Яндекса, а не с Google.
В данный момент с сервисом взаимодействуют программы:
- KeyAssort – программа для профессиональной кластеризации семантического ядра;
- TopSite – программа для проверки позиций сайтов в поисковых системах;
- Key Collector (4 версия) — комбайн для сбора семантического ядра;
- Majento PositionMeter — бесплатный сборщик позиций;
- SERP Parser — программа для сбора позиций.
- XMLRiver.Parser — это наша внутренняя программа парсер, которая позволяет с помощью сервиса собрать данные и выгрузить их в удобном формате csv.
Парсер также даёт возможность проверить индексацию страниц в Google. Для этого надо загрузить список проверяемых документов и нажать «Проверка индексации».

 от живой выдачи")

