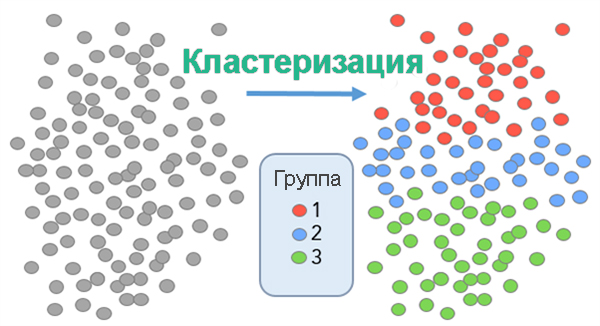
Кластеризация (группировка) ключевых слов
Привет, друзья!
В этой статье хотелось бы поговорить о качественной кластеризации семантического ядра.
Кластеризация – это автоматическое объединение ключевых слов в группы на основании данных поисковой выдачи.
Зачем это нужно? После сбора семантики, ключевые слова надо объединить в группы по одинаковому смыслу. Так, чтобы при распределении этих групп по сайту, определённые страницы отвечали одному желанию (интенту) пользователя. Если это делать «вручную», то seo-специалисту нужно досконально знать анализируемую тематику, чтобы ориентироваться в синонимах и поведении пользователей. Например, слова «алоэ» и «столетник» несут один и тот же смысл, но без этого знания сделать качественную кластеризацию не получится. Для того, чтобы не вдаваться в подробности тематики и нужна автоматическая кластеризация, т.к. поисковые системы уже давно и в подробностях изучили нюансы подавляющего большинства тематик и на основе этого знания мы можем сделать правильную группировку.
Методы и алгоритмы кластеризации
В данный момент у большинства инструментов для кластеризации есть 2 основных алгоритма: hard и soft. У некоторых инструментов, таких как KeyAssort, есть ещё middle – нечто среднее между hard и soft, поэтому на его примере мы и будем рассматривать кластеризацию.
Чем эти методы отличаются и когда применять тот или иной алгоритм?
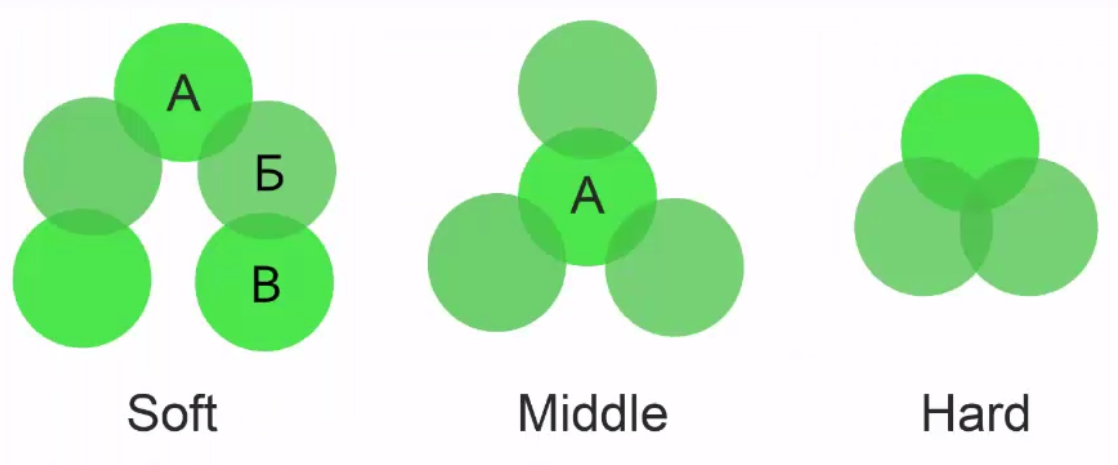
Все методы кластеризации используют один и тот же алгоритм – для каждой фразы собирают топ поисковой системы и сравнивают url всех фраз между собой. Но отличия всё же есть в методах сравнения.
Soft кластеризация
При этом методе сравниваются url у всех фраз между собой. У запроса А может быть общий набор url с запросом Б, а у запроса Б – общий набор url с запросом В. При этом запрос А и В могут не иметь общих URL. Софт метод подходит для информационных сайтов с низким уровнем конкуренции в тематике.
Middle кластеризация
При этом методе берётся один центральный запрос А и с ним сравниваются остальные фразы на предмет совпадения URL. Этот метод подходит для информационных сайтов с высоким уровнем конкуренции либо для коммерческих сайтов с низким уровнем конкуренции.
Hard кластеризация
При этом методе фразы будут объединены в группу только при совпадении общего для всех фраз набора URL. Хард метод характеризуется высокой точностью и подходит коммерческим сайтам с высоким уровнем конкуренции.
Сила (порог) кластеризации
Точность или порог кластеризации (сила по SERP) — это параметр, который отвечает за то, сколько одинаковых URL нужно в топ-10 поисковой системы, чтобы ключевые слова попали в один кластер, т.е. отвечает за то, как сильно должны быть похожи запросы для попадания в одну группу. Чем выше этот параметр – тем точнее получаются группы, но при этом меньше в размерах.
Инструменты для кластеризации запросов
В данный момент на рынке кластеризации свои услуги предлагают онлайн сервисы и десктопные программы. Из основных сервисов, основываясь на экспериментах и отзывах seo-специалистов можно выделить:
- TopVisor;
- Rush Analytics;
- Just-Magic;
- Serpstat;
- SemParser.
Из программ для качественной кластеризации можно отметить только KeyAssort.
Учитывая, что KeyAssort выигрывает в цене кластеризации, а часто и в качестве, для этой статьи был выбран именно этот инструмент.
Пошаговая кластеризация на реальном примере
После сбора семантического ядра, его надо распределить по группам и составить структуру будущего сайта, если мы делаем семантику для нового сайта.
В самом начале нам надо принять решение, будем ли мы составлять структуру на основании распределённого по группам семантического ядра или на основании логики/конкурентов. Если второй вариант, то загружаем в программу готовую структуру, которую предварительно составили.
Если же первый вариант, то импортируем ядро, а структуру будем составлять после кластеризации, глядя на готовые группы. В данном примере мы импортируем файл с параметрами, т.к. нам важна частота запросов для дальнейшего принятия решения относительно того, какие группы мы будем использовать в первую очередь, а какие не будем использовать вообще.
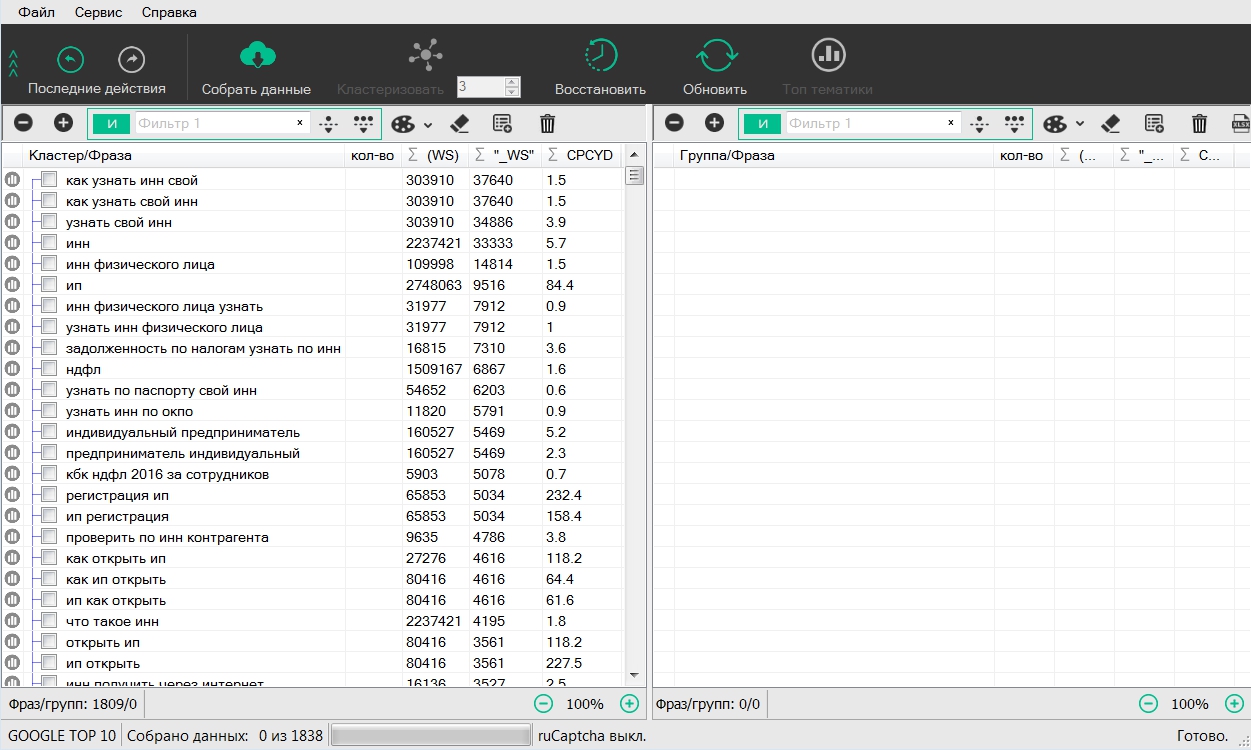
Вот как это будет выглядеть после импорта:
Т.к. последнее время Google становится всё популярнее и популярнее Яндекса, принимаем решение собирать данные именно с google.
После регистрации на сервисе XMLRiver, пополняем счёт (1), в разделе «Покупка запросов» (2) копируем ссылку для запросов (3):
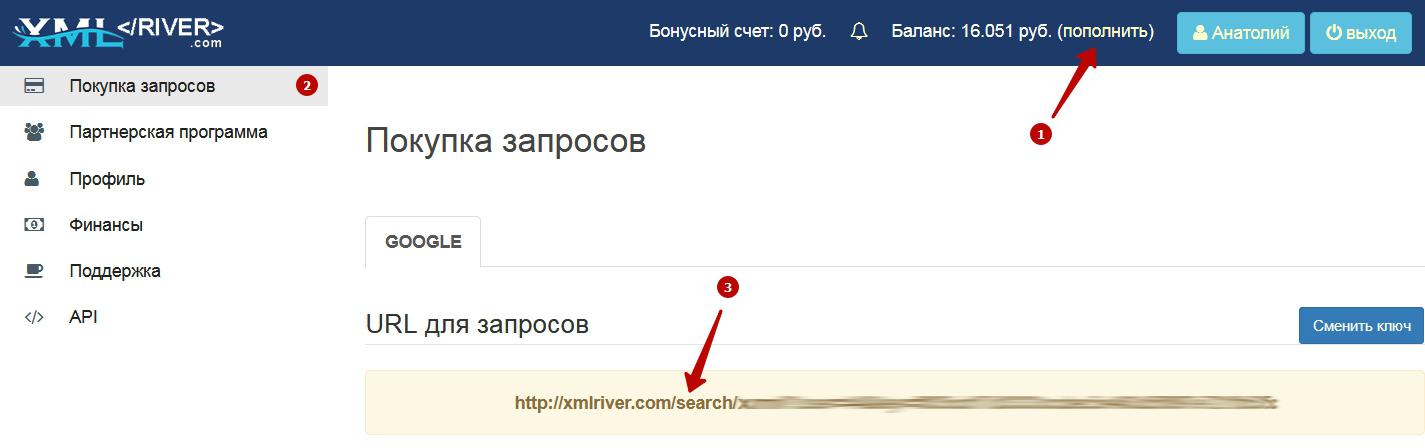
Эту ссылку нам надо вставить в окно настроек программы (1), установить топ10 (2) и другие настройки, связанные с местоположением:
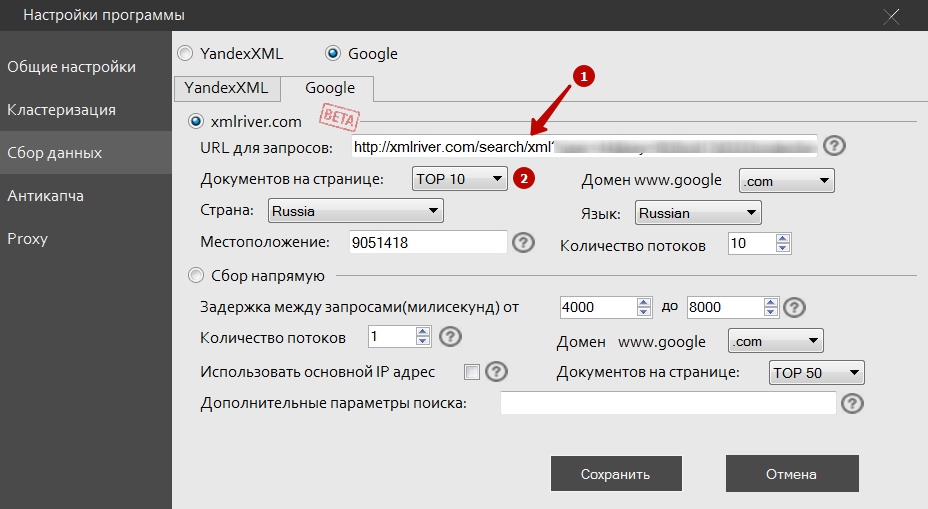
Относительно топ10 – больше ставить нет никакого смысла, у Гугла в подавляющем большинстве случаев достаточно качественная выдача и увеличение количества собранных данных не приведёт к улучшению качества кластеризации.
Региональность можно указать как в софте, так и в настройках сервиса. Однако обратите внимание, что если эти данные указаны и в одном и во втором месте, приоритет будет у указанных в программе.
Если указываете местоположение в программе, числовое значение этого местоположения надо брать из файла на скриншоте.
Также стоит упомянуть, что если вы хотите собрать данные, например, по Москве, то домен надо выбирать ru, язык — Russian, страну – Russia. Иначе данные могут быть не точны.
После описанных выше настроек и сбора данных переходим непосредственно к процессу кластеризации. Тематика у нас не самая конкурентная, поэтому выбираем вид кластеризации Middle с миграцией (это можно сделать горячими клавишами ctrl+Tab) и попробуем силу группировки 3. Если в результате получится слишком много групп с одним поисковым интентом, надо уменьшить силу кластеризации, если же фразы в группах будут слишком разнородными – увеличить и снова провести процесс кластеризации. Для этого заново собирать данные не требуется, достаточно нажать на кнопку «Восстановить», при этом семантическое ядро вернётся в первоначальное состояние до процесса кластеризации.
В нашем случае результат был достаточно хорошим, и, после небольших ручных правок, вырисовалась картина по структуре сайта, которая сразу была создана, а группы распределены по своим категориям.


 от живой выдачи")
